多国語対応(UTF-8対応)
1)HTMLドキュメント
HTMLドキュメントの文字コードの決定は、proles.iniの[CGI]セクションの「Charset」にて行います。デフォルトは「UTF-8」です。
2)データベース
2.1)Access
特に何もせずに、多国語に対応しています。
2.2)MySQL(Ver8以降)、
DBの作成時にCharSetをUTF-8と指定します。utf8mb4としても、ODBCドライバの制約で4byte utf8の文字は「?」文字に置換されます。
2.3)PostgreSQL(Ver9以降)、
DBの作成時にCharSetをUTF-8と指定します。
2.4)DB2(Ver9以降)
多国語用の特別な設定はありません。
2.5)ORACLE(11g以降)
多国語に対応させるフィールド(列)をncharやnvarcharに設定します。但し、データベース・キャラクター・セットをUTF-8にしてDBを作成するとともに、環境変数をNLS_LANG=JAPANESE_JAPAN.UTF8とセットします。
2.5)SQL
Server(2005以降)
多国語に対応させるフィールド(列)をncharやnvarcharに設定し、SQL文の多国語対応の文字列定数には、Nプレフィックスを付けることが必要です。
XCuteでは、ncharやnvarcharを指定したフィールドを特定する為、下記のように手動でNational
を指定します。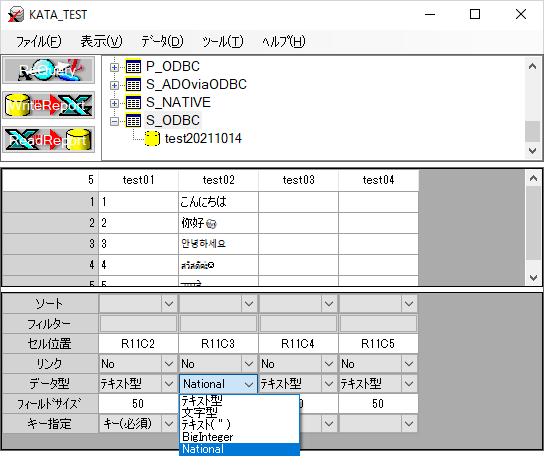
Nプレフィックスについては、通常のFilterコマンドはXCute内部で書式を整えますので何ら変更はありません。Filter()では、括弧内がそのままSQL文のWhere句に追加されますので、Nプレフィックスは必要です。CHG_SQLコマンドも同様、Nプレフィックスは必要です。下記は、Nプレフィックスを付けたSQL文です。
SELECT
* FROM MyM WHERE (nvarc LIKE N'%ÀÁ%')
XCuteのフィルターでは、Nプレフィックスは下記のように指定します。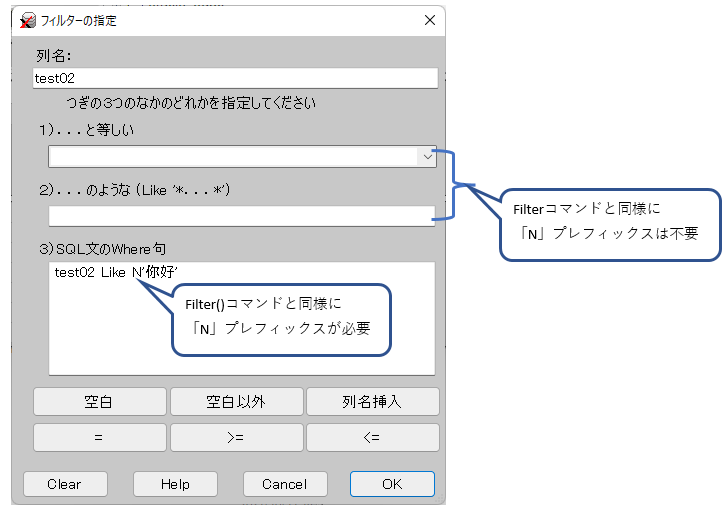
参照
○リビジョン管理による排他制御
○各種データベース対応
○SQL文の指定パネル
○EXT_SQLコマンド
○DBの排他制御